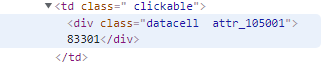
I'm attempting to locate the ID on the webpage using innerText HTML element and the browser I am using is Chrome. Anything different I should try or any reason why my bot would be failing? Thanks in advance and let me know if you have any questions!
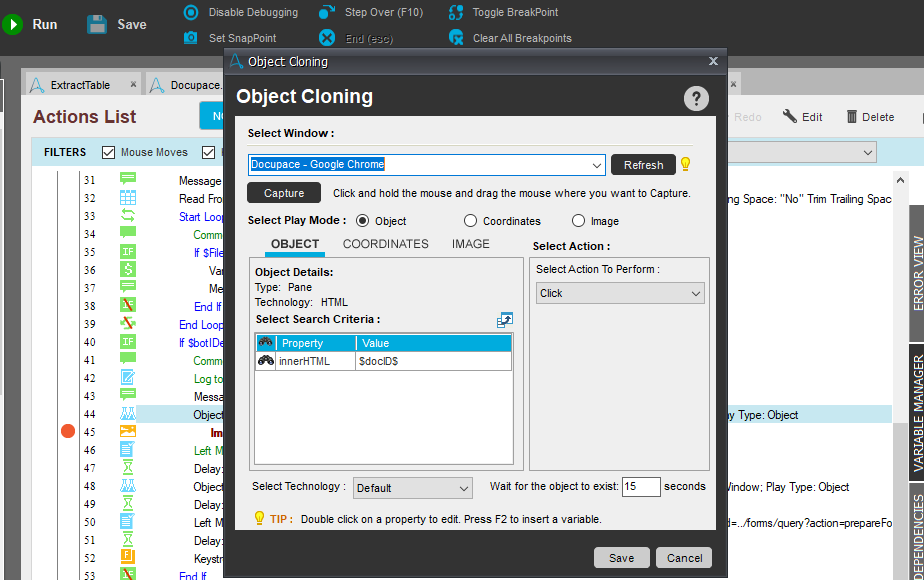
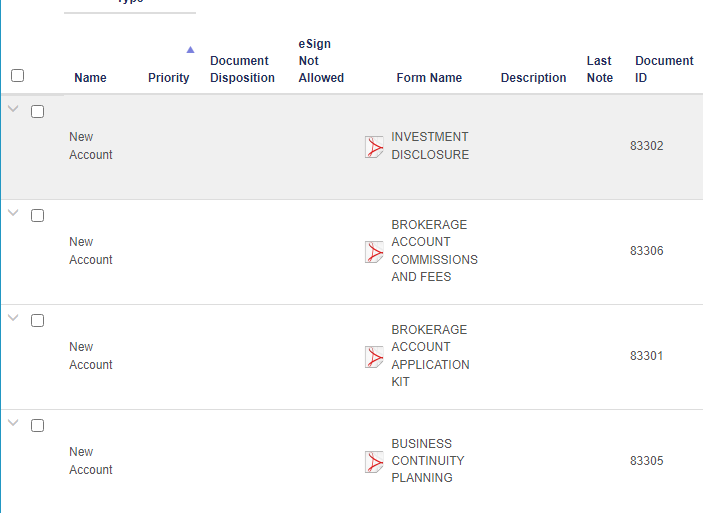

I'm attempting to locate the ID on the webpage using innerText HTML element and the browser I am using is Chrome. Anything different I should try or any reason why my bot would be failing? Thanks in advance and let me know if you have any questions!
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.