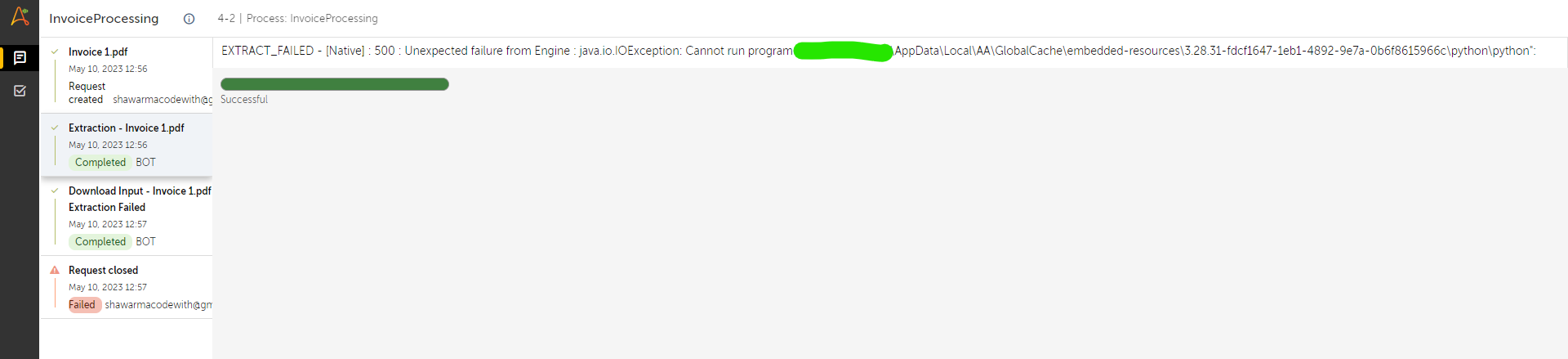
Getting Extract failed error "EXTRACT_FAILED - [Native] : 500 : Unexpected failure from Engine : java.io.IOException: Cannot run program" when Processing scanned documents. Can someone please help?

Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.